- E o vírus... Levou
- Apertem os cintos, o sistema caiu.
- Desejo de Formatar IV.
- O PC de Rosemary.
- Deletar Nunca, formatar jamais.
- A primeira Conexão de um Homem.
- Duro de Deletar.
- Querida, formatei o winchester.
- A insustentável leveza do C.
- Log para entrar, Reze para sair.
- Se meu windows funcionasse.
- A mão que balança o mouse.
- A vida é tela.
- HD da Corrupção.
- Teclando a Vida a doidado.
- Por uns dados a mais.
- Duelo de programas.

Saturday, 31 December 2011
OS FILMES CAMPEÕES DA TURMA DE INFORMÁTICOS
Thursday, 29 December 2011
Mobilidade: ai que medo!
Começam os preparativos dos brasileiros que participarão na NRF2012 – o maior evento do mundo de tecnologia e varejo. O evento será em Nova York com um frio típico de menos 15 graus, mas com temas extremamente acalorados nas palestras. Olhando a grade de conteúdo percebemos uma evolução nítida na temática de mobilidade.
Em janeiro de 2010 eles trataram mobilidade como sendo uma tendência inexorável, que traria grandes desafios e vantagens para todos os tipos de empresas, incluindo o varejo.
Em janeiro de 2011 apresentaram os primeiros casos de sucesso de algumas marcas que estavam “experimentando” mobilidade. Empresas como Target, Best Buy, Whole Foods, Sephora, GAP, Blockbuster, Walmart e Starbucks desenvolveram aplicativos para o iPhone, permitindo que o consumidor localizasse a loja mais próxima, recebesse informações e promoções quando estivesse dentro da loja, fizesse pagamento dos itens comprados e recebesse atendimento pós-vendas, fechando o ciclo e fidelizando o cliente.
O Grupo Casino mostrou o uso da mobilidade para criar o conceito de gôndola eletrônica, leiloando espaço entre os fornecedores. Red Laser e Shop Savvy criaram aplicativos usando a câmera do iPhone para tirar foto do código de barras e mostrar ao consumidor todos os detalhes do produto com notas e avaliações de outros consumidores, permitindo, inclusive, comparação de funcionalidades, preços e promoções entre produtos ou lojas concorrentes.
Em 2012, muitas sessões serão de mesas redondas onde os empresários discutirão o impacto atual da mobilidade em seus negócios. É como seu fosse um grande “Ihhhhh…fu…tudo o que a gente falava que ia acontecer com mobilidade…aconteceu. E sabe o que é pior? A gente não se preparou para isto.”
Os empresários estão desesperados, porque os consumidores contam com um grande aliado nas mãos: o acesso à informação, via smartphone, muda o poder de barganha. Você vai até uma loja, vê o produto, tira foto do código de barra e um aplicativo te diz se tem alguma loja próxima com o mesmo item e preço mais barato. O vendedor típico (sem tablet) tem muito menos informação do produto que o cliente. As empresas não querem se transformar em show-room, onde o consumidor vai ver a mercadoria e compra em outro lugar. Para evitar isto, terão que tomar o pé da situação e transformar o varejo.
A preocupação agora é como permear a mobilidade para a empresa inteira, ou seja, como fazer com que o departamento de marketing entenda e use o conceito a favor das vendas. Como melhorar o desempenho operacional da empresa usando a mobilidade para que os sistemas se comuniquem com os colaboradores – apoiando-os nas tarefas do dia a dia e melhorando o seu desempenho.
Esta é uma temática complexa. Envolve pouca tecnologia e muito conhecimento de negócios.
A tecnologia da mobilidade é simples e já está absorvida, mas muitas empresas terão que mudar radicalmente seus processos e talvez até o modelo de negócios. E quem serão os profissionais capazes de ajudar as empresas neste momento? Será que os profissionais tradicionais de operações, marketing e vendas conseguirão remodelar as empresas para esta nova realidade? Eu duvido…Será que existem empresas de consultoria capazes de fazer isto e em número suficiente para atender à demanda de mercado? Eu duvido…
E, aqui no Brasil, a coisa está pior ainda, porque sequer passamos do estágio de testes preliminares da mobilidade, que os americanos fizeram ao longo de 2010. Temos pouquíssimos casos de sucesso e, obviamente, pouquíssimos casos para estudar o impacto da tecnologia nos negócios. Portanto, o evento da NRF2012 será de fundamental importância para as empresas brasileiras aprenderem com os americanos o que fazer com a mobilidade, tanto do ponto de vista de tecnologia, quanto de negócios. Vejo vocês em Nova York.
Wednesday, 28 December 2011
Saber é poder! Descubra a maneira de enfrentar os desafios de TI e de telecomunicações mais importantes com soluções personalizadas
Uma arquitetura aperfeiçoada para Data Centers de alta densidade e alta eficiência

Tuesday, 27 December 2011
Tubes dans psql (suite)
Considérons une requête sql, contenue dans un fichier et dont le résultat est envoyé par un tube vers la commande awk.
Le script à utiliser par awk dépend de la configuration.
Ainsi, si un titre a été défini par une méta-commande, la première ligne avec des données sera la ligne # 4 (au lieu de # 3).
Si de plus le style de bordure est de type 2, ce sera la ligne # 5.
C'est pourquoi il peut être utile de placer dans un fichier contenant une instruction de redirection vers un tube, les méta-commandes de configuration comme par exemple:
\pset title Rapport
Pour éviter de polluer l'output par des messages tels que:
Le titre est « Rapport »
il convient alors de définir en premier la variable d'environnement QUIET.
D'autre part, on voudrait aussi après exécution de la requêtre rétablir la configuration par défaut, de sorte qu'un tel fichier pourrait ressembler à ceci:
Ci dessus un script awk adapté à la présence d'un titre et à un style de bordure de niveau 2, servant à la mise en forme du titre et à l'impression d'une ligne de séparation avant une ligne "TOTAL" éventuelle:
La ligne u, au départ une copie de t, qui sera imprimée juste avant et juste après le titre, est modifiée dans un premier temps en remplaçant par a de tout ce qui n'appartient pas à la classe prédéfinie [:space:], et ensuite en remplaçant aussi (par a) les espaces qui sont au milieu de la chaîne des a (les espaces qui étaient contenus dans le titre).
Notes:
On obtient dans le cas d'un style de ligne unicode:

Le script peut être utilisé même en l’absence de ligne "TOTAL": il sert alors simplement à mettre en forme le titre.
Si le style de bordure est de niveau 1, il faut attendre la ligne 3 pour récupérer le caractère servant à tracer les lignes.
Le script (qui pourrait s'appeler titre-border-1.awk) se présente alors comme ceci:
Envisageons maintenant d'envoyer le résultat d'une requête vers un tube afin d'en numéroter les lignes avec cette méta-commande:
Nous utilisons printf afin que les numéros des lignes soient justifiés à droite: on imprime d'abord NR en tant que nombre décimal précédé d'espaces jusqu'à atteindre la longueur 5 (%5d), un caractère de tabulation (\t), ensuite la ligne reçue en input en tant que chaîne de caractères (%s).
Notons que printf (contrairement à print) ne met pas de caractère nouvelle ligne (\n) à la fin de son envoi. Il doit donc être explicitement ajouté.
En présence d'un titre et avec un style de bordure de niveau 1, on obtient:

Bien sûr, on voudrait seulement numéroter les lignes de données et en plus mettre en forme le titre et séparer la ligne "TOTAL" éventuelle du reste.
Pour ce faire, il suffit par exemple, d'adapter le script précédent (qui convient pour un style de bordure de niveau 1):
L'utilisation du script ci-dessus nous donne:

Adapter pour la numérotation le script convenant pour le style de bordure de niveau 2 est un peu plus ardu.
Le problème est d'éviter la numérotation de la dernière ligne non vide (qui fait partie du cadre):
Et voici le résultat:
Les scripts awk présentés ici dépendent certes du style de bordure et de la présence d'un titre, mais ils sont indépendants du style de ligne.
Par exemple avec un autre style de ligne, une autre table et un autre titre, l'utilisation du même script donne ceci:

Le script à utiliser par awk dépend de la configuration.
Ainsi, si un titre a été défini par une méta-commande, la première ligne avec des données sera la ligne # 4 (au lieu de # 3).
Si de plus le style de bordure est de type 2, ce sera la ligne # 5.
C'est pourquoi il peut être utile de placer dans un fichier contenant une instruction de redirection vers un tube, les méta-commandes de configuration comme par exemple:
\pset title Rapport
Pour éviter de polluer l'output par des messages tels que:
Le titre est « Rapport »
il convient alors de définir en premier la variable d'environnement QUIET.
D'autre part, on voudrait aussi après exécution de la requêtre rétablir la configuration par défaut, de sorte qu'un tel fichier pourrait ressembler à ceci:
\set QUIET
\pset numericlocale on
\pset footer off
\pset linestyle u
\pset title 'Rapport'
\pset border 2
\o | awk -f titre-border-2.awk | tee Rapport.txt
--++++++++++++++++++++++++++++++++++++++++++++++
-- Début de la requête
--++++++++++++++++++++++++++++++++++++++++++++++
SELECT ....
......
;
--++++++++++++++++++++++++++++++++++++++++++++++
-- Fin de la requête
--++++++++++++++++++++++++++++++++++++++++++++++
\o
\pset footer
\pset title
\pset border 1
\unset QUIET
(Notons l'utilisation, comme il se doit en sql, de -- pour commenter une ligne)\pset numericlocale on
\pset footer off
\pset linestyle u
\pset title 'Rapport'
\pset border 2
\o | awk -f titre-border-2.awk | tee Rapport.txt
--++++++++++++++++++++++++++++++++++++++++++++++
-- Début de la requête
--++++++++++++++++++++++++++++++++++++++++++++++
SELECT ....
......
;
--++++++++++++++++++++++++++++++++++++++++++++++
-- Fin de la requête
--++++++++++++++++++++++++++++++++++++++++++++++
\o
\pset footer
\pset title
\pset border 1
\unset QUIET
Ci dessus un script awk adapté à la présence d'un titre et à un style de bordure de niveau 2, servant à la mise en forme du titre et à l'impression d'une ligne de séparation avant une ligne "TOTAL" éventuelle:
# Sauvegarde du titre dans t et u
NR == 1 {
t=$0
u=t
}
# Récupération du caractère pour tracer les lignes
# Impression du titre
NR == 2 {
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
}
# Sauvegarde ligne de séparation dans y
NR == 4 {
y=$0
}
/^..TOTAL/ {
print y
}
# Ne plus imprimer le titre (ligne # 1)
NR > 1
Le titre contenu dans $0 puis sauvegardé dans t est précédé du nombre d'espaces qui convient pour qu'il soit centré.NR == 1 {
t=$0
u=t
}
# Récupération du caractère pour tracer les lignes
# Impression du titre
NR == 2 {
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
}
# Sauvegarde ligne de séparation dans y
NR == 4 {
y=$0
}
/^..TOTAL/ {
print y
}
# Ne plus imprimer le titre (ligne # 1)
NR > 1
La ligne u, au départ une copie de t, qui sera imprimée juste avant et juste après le titre, est modifiée dans un premier temps en remplaçant par a de tout ce qui n'appartient pas à la classe prédéfinie [:space:], et ensuite en remplaçant aussi (par a) les espaces qui sont au milieu de la chaîne des a (les espaces qui étaient contenus dans le titre).
Notes:
- La lecture du billet "Expressions régulières" pourrait être utile en cas de difficulté de compréhension d'une notation telle que [^[:space:]]
- Il arrive que la classe [:space:] ne soit pas reconnue par le programme awk qui est appelé (c'est le cas chez Ubuntu où /etc/alternatives/awk pointe vers /usr/bin/mawk). Il convient alors d'installer gawk.
- Dans ce script (et dans les suivants) on pourrait remplacer [^[:space:]] par la notation abrégée \S (pas chez Ubuntu, même avec gawk installé).
- La classe [:space:] comprend outre les espaces, les caractères de contrôle tabulation (\t), tabulation verticale (\v), saut de page (\f), retour chariot (\r), nouvelle ligne (\n). Mais à l'intérieur du script, awk travaille sur des lignes qui ont été débarrassées de leur \n final. Celui-ci est remis par l'action "print".
- gsub retourne 1 en cas de substitution effectuée: il devient alors une condition vérifiée pour la commande while (qui est utile lorsque le titre comprend plusieurs espaces successifs).
- a a représente la concaténation de a et de a.
On obtient dans le cas d'un style de ligne unicode:
Le script peut être utilisé même en l’absence de ligne "TOTAL": il sert alors simplement à mettre en forme le titre.
Si le style de bordure est de niveau 1, il faut attendre la ligne 3 pour récupérer le caractère servant à tracer les lignes.
Le script (qui pourrait s'appeler titre-border-1.awk) se présente alors comme ceci:
# Sauvegarde du titre dans t et u
NR == 1 {
t=$0
u=t
}
# Sauvegarde des en-têtes dans h
NR == 2 {
h=$0
}
# Sauvegarde de la ligne de séparation dans y
# Récupération du caractère pour tracer les lignes
# Impression du titre puis des en-têtes
NR == 3 {
y=$0
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print h
}
/^.TOTAL/ {
print y
}
# Ne plus imprimer le titre et les en-têtes
NR > 2
NR == 1 {
t=$0
u=t
}
# Sauvegarde des en-têtes dans h
NR == 2 {
h=$0
}
# Sauvegarde de la ligne de séparation dans y
# Récupération du caractère pour tracer les lignes
# Impression du titre puis des en-têtes
NR == 3 {
y=$0
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print h
}
/^.TOTAL/ {
print y
}
# Ne plus imprimer le titre et les en-têtes
NR > 2
Envisageons maintenant d'envoyer le résultat d'une requête vers un tube afin d'en numéroter les lignes avec cette méta-commande:
\o | awk '{printf("%5d\t%s\n", NR, $0)}'
Nous utilisons printf afin que les numéros des lignes soient justifiés à droite: on imprime d'abord NR en tant que nombre décimal précédé d'espaces jusqu'à atteindre la longueur 5 (%5d), un caractère de tabulation (\t), ensuite la ligne reçue en input en tant que chaîne de caractères (%s).
Notons que printf (contrairement à print) ne met pas de caractère nouvelle ligne (\n) à la fin de son envoi. Il doit donc être explicitement ajouté.
En présence d'un titre et avec un style de bordure de niveau 1, on obtient:
Bien sûr, on voudrait seulement numéroter les lignes de données et en plus mettre en forme le titre et séparer la ligne "TOTAL" éventuelle du reste.
Pour ce faire, il suffit par exemple, d'adapter le script précédent (qui convient pour un style de bordure de niveau 1):
# Sauvegarde du titre dans t et u
NR == 1 {
t= "\t" $0
u=t
}
# Sauvegarde des en-têtes
NR == 2 {
h= "\t" $0
}
# Sauvegarde de la ligne de séparation dans y
# Impression du titre, des en-têtes et de la ligne de séparation qui suit
NR == 3 {
y= "\t" $0
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print h
print y
}
/^.TOTAL/ {
print y
print "\t" $0
}
# Numéroter puis imprimer les données
# Ne pas procéder pour la ligne TOTAL éventuelle, ni pour les lignes vides
NR > 3 && !/^.TOTAL/ && !/^$/ {
n++
printf("%5d\t%s\n", n, $0)
}
# Impression des lignes vides
/^$/
(u comprend maintenant un caractère de tabulation, mais comme ce caractère fait partie de la classe [:space:], cela ne change rien en ce qui concerne le résultat de gsub)NR == 1 {
t= "\t" $0
u=t
}
# Sauvegarde des en-têtes
NR == 2 {
h= "\t" $0
}
# Sauvegarde de la ligne de séparation dans y
# Impression du titre, des en-têtes et de la ligne de séparation qui suit
NR == 3 {
y= "\t" $0
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print h
print y
}
/^.TOTAL/ {
print y
print "\t" $0
}
# Numéroter puis imprimer les données
# Ne pas procéder pour la ligne TOTAL éventuelle, ni pour les lignes vides
NR > 3 && !/^.TOTAL/ && !/^$/ {
n++
printf("%5d\t%s\n", n, $0)
}
# Impression des lignes vides
/^$/
L'utilisation du script ci-dessus nous donne:
Adapter pour la numérotation le script convenant pour le style de bordure de niveau 2 est un peu plus ardu.
Le problème est d'éviter la numérotation de la dernière ligne non vide (qui fait partie du cadre):
# Sauvegarde du titre dans t et u
NR == 1 {
t= "\t" $0
u=t
}
# Impression du titre et de la partie supérieure du cadre
NR == 2 {
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print "\t" $0
}
# Impression des en-têtes
NR == 3 {
print "\t" $0
}
# Sauvegarde dans y et impression de la ligne de séparation
NR == 4 {
y= "\t" $0
print y
}
/^..TOTAL/ {
print y
print "\t" $0
}
# Impression de la partie inférieure du cadre
NR > 4 && substr($0,2,1)==a {
print "\t" $0
}
# Numéroter puis imprimer les données
# Ne pas procéder pour la ligne TOTAL éventuelle, ni pour les lignes vides
# ni pour les lignes de cadre
NR > 4 && !/^..TOTAL/ && !/^$/ && substr($0,2,1)!=a {
n++
printf("%5d\t%s\n", n, $0)
}
# Impression ligne vide
/^$/
NR == 1 {
t= "\t" $0
u=t
}
# Impression du titre et de la partie supérieure du cadre
NR == 2 {
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print "\t" $0
}
# Impression des en-têtes
NR == 3 {
print "\t" $0
}
# Sauvegarde dans y et impression de la ligne de séparation
NR == 4 {
y= "\t" $0
print y
}
/^..TOTAL/ {
print y
print "\t" $0
}
# Impression de la partie inférieure du cadre
NR > 4 && substr($0,2,1)==a {
print "\t" $0
}
# Numéroter puis imprimer les données
# Ne pas procéder pour la ligne TOTAL éventuelle, ni pour les lignes vides
# ni pour les lignes de cadre
NR > 4 && !/^..TOTAL/ && !/^$/ && substr($0,2,1)!=a {
n++
printf("%5d\t%s\n", n, $0)
}
# Impression ligne vide
/^$/
Et voici le résultat:
Les scripts awk présentés ici dépendent certes du style de bordure et de la présence d'un titre, mais ils sont indépendants du style de ligne.
Par exemple avec un autre style de ligne, une autre table et un autre titre, l'utilisation du même script donne ceci:
Wednesday, 21 December 2011
Tubes dans psql
Un terminal psql est un terminal connecté à une base de données PostgreSQL qui permet d'exécuter des instructions sql.

Nous avons aussi créé une vue opérationv avec l'instruction
Avec cette vue, la dernière requête du billet précédent, qui paraissait monstrueuse, prend tout de suite un visage plus sympathique:
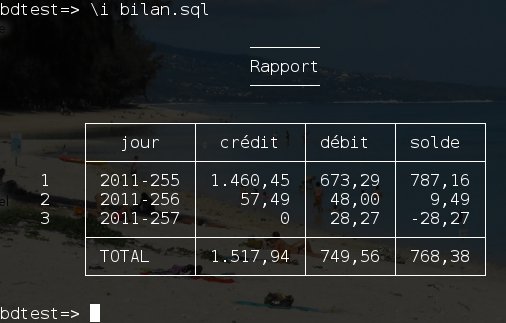
Nous avons placé cette requête dans le fichier bilan.sql.
Exécutons la:

Nous retrouvons bien le même résultat que précédemment.
Avant de procéder avec bilan.sql, nous avons exécuté deux méta-commandes. La méta-commande "\pset numericlocale" a déjà été commentée précédemment.
Quant à la méta-commande "\pset footer off", il suffit de jeter un coup d'oeil distrait sur le résultat situé à la fin du billet précédent pour saisir quel est son objet.
On voudrait améliorer le résultat affiché et obtenir par exemple quelque chose comme:
Pour arriver à nos fins, nous allons à l'aide d'un tube envoyer le résultat vers la commande:
Instruction 1: elle comprend deux actions conditionnées par NR == 1, donc qui s'exécutent seulement à la lecture de la première ligne.
Action 1: construction d'une chaîne d'espaces dans le but de centrer le mot "Bilan"
Action 2: impression du titre ("\n" est le caractère de contrôle nouvelle ligne)
Instruction 2: on sauvegarde dans y la ligne lue (ligne 2) dans laquelle on a remplacé tous les "-" par des "=".
Les deux instructions restantes sont inchangées.
Plaçons en tête du fichier bilan.sql la méta-commande:
\o | awk -f bilan.awk
Testons le résultat:

Si nous voulons envoyer le résultat obtenu vers un fichier bilan.txt tout en gardant l'affichage à l'écran, il suffit d'utiliser un deuxième tube:
\o | awk -f bilan.awk | tee bilan.txt
Il nous est bien sûr loisible de ne rien envoyer vers l'écran:
\o | awk -f bilan.awk > bilan.txt
On peut aussi y introduire des méta-commandes: commandes précédées d'une barre oblique inversée (backslash). Certaines méta-commandes ont déjà été présentées dans ce blog telle
\o [FICHIER]
qui envoie le résultat des requêtes ultérieures dans le fichier FICHIER.
Mais cette méta-commande permet également d'envoyer les résultats des requêtes dans un tube (pipe). Dans ce billet, nous allons montrer comment tirer parti de cette dernière possibilité.
Connectons nous à notre base de données de test et retrouvons grâce à la méta-commande \dS les caractéristiques de la table opération:
Nous avons aussi créé une vue opérationv avec l'instruction
CREATE VIEW opérationv
AS
SELECT jour, seq,
CASE
WHEN montant > 0 THEN montant
ELSE 0
END AS crédit,
CASE
WHEN montant < 0 THEN -montant
ELSE 0
END AS débit,
contrepartie
FROM opération ;
AS
SELECT jour, seq,
CASE
WHEN montant > 0 THEN montant
ELSE 0
END AS crédit,
CASE
WHEN montant < 0 THEN -montant
ELSE 0
END AS débit,
contrepartie
FROM opération ;
Avec cette vue, la dernière requête du billet précédent, qui paraissait monstrueuse, prend tout de suite un visage plus sympathique:
SELECT jour, sum(crédit) AS crédit,
sum(débit) AS débit,
sum(crédit) - sum(débit) AS solde
FROM
opérationv
GROUP BY jour
UNION
SELECT 'TOTAL' AS jour, sum(crédit) AS crédit,
sum(débit) AS débit,
sum(crédit) - sum(débit) AS solde
FROM
opérationv
ORDER BY jour
;
sum(débit) AS débit,
sum(crédit) - sum(débit) AS solde
FROM
opérationv
GROUP BY jour
UNION
SELECT 'TOTAL' AS jour, sum(crédit) AS crédit,
sum(débit) AS débit,
sum(crédit) - sum(débit) AS solde
FROM
opérationv
ORDER BY jour
;
Nous avons placé cette requête dans le fichier bilan.sql.
Exécutons la:
Nous retrouvons bien le même résultat que précédemment.
Avant de procéder avec bilan.sql, nous avons exécuté deux méta-commandes. La méta-commande "\pset numericlocale" a déjà été commentée précédemment.
Quant à la méta-commande "\pset footer off", il suffit de jeter un coup d'oeil distrait sur le résultat situé à la fin du billet précédent pour saisir quel est son objet.
On voudrait améliorer le résultat affiché et obtenir par exemple quelque chose comme:
jour | crédit | débit | solde
----------+----------+--------+--------
2011-255 | 1.460,45 | 673,29 | 787,16
2011-256 | 57,49 | 48,00 | 9,49
2011-257 | 0 | 28,27 | -28,27
=======================================
TOTAL | 1.517,94 | 749,56 | 768,38
----------+----------+--------+--------
2011-255 | 1.460,45 | 673,29 | 787,16
2011-256 | 57,49 | 48,00 | 9,49
2011-257 | 0 | 28,27 | -28,27
=======================================
TOTAL | 1.517,94 | 749,56 | 768,38
Pour arriver à nos fins, nous allons à l'aide d'un tube envoyer le résultat vers la commande:
awk '/^ TOTAL/ {while (a++<=length($0)) x=x "="; print x }; 1'
Un billet entier est consacré dans ce blog à awk.
Le script de la commande awk (ce qui est compris entre les deux apostrophes) comprend ici deux instructions (séparées par le point-virgule qui est devant le 1).
Rappelons qu'une instruction awk est constituée d'une condition suivie de une où plusieurs actions qui s'exécutent seulement si la condition est vérifiée.
awk va lire une à une les différentes lignes du résultat et effectuer (éventuellement) les actions comprises dans les instructions.
Analysons la première instruction:
/^ TOTAL/ {while (a++<=length($0)) x=x "="; print x }
Elle comprend une condition suivie de deux actions placées entre crochets et séparées par un point-virgule.
En rouge la condition: avoir le mot "TOTAL" en deuxième position.
En bleu l'action 1: construire avec "=" une chaîne de longueur égale à la longueur de la ligne lue (qui se trouve dans la variable $0).
En vert l'action 2: imprimer (envoyer vers la sortie standard) la chaîne qui vient d'être construite.
La deuxième instruction est très simple: elle comprend simplement la condition "1" qui est toujours vérifiée et réalise donc à chaque fois l'action par défaut "print".
Cette deuxième instruction sert simplement à imprimer (envoyer vers la sortie standard) tout ce qui a été lu.
Ajoutons en tête du fichier bilan.sql, la méta-commande:
\o | awk '/^ TOTAL/ {while (a++<=length($0)) x=x "="; print x }; 1'
ce qui aura pour effet d'envoyer via le tube " | " l'output de la requête sql vers awk.
Et pour remettre les chose en état après exécution du query, terminons le fichier avec
\o
Et voilà:

Il y a plus simple.
Par exemple envoyer la sortie vers
Cette fois le script awk comprend trois instructions.
Instruction 1: si la ligne lue est la ligne 2, la sauvegarder dans y
Instruction 2: si la ligne lue contient "TOTAL" en position 2, imprimer y
Instruction 3: imprimer de manière inconditionnelle la ligne lue.
Et voici le résultat obtenu:

Il est possible d'améliorer encore le résultat (pour par exemple afficher un titre), mais cela va compliquer (un tout petit peu) le script awk. Pour plus de clarté, plaçons le script modifié dans un fichier que nous appelons bilan.awk (les conditions sont en rouge):
Ajoutons en tête du fichier bilan.sql, la méta-commande:
\o | awk '/^ TOTAL/ {while (a++<=length($0)) x=x "="; print x }; 1'
ce qui aura pour effet d'envoyer via le tube " | " l'output de la requête sql vers awk.
Et pour remettre les chose en état après exécution du query, terminons le fichier avec
\o
Et voilà:
Il y a plus simple.
Par exemple envoyer la sortie vers
awk 'NR==2 {y=$0};/^ TOTAL/ {print y};1'
Instruction 1: si la ligne lue est la ligne 2, la sauvegarder dans y
Instruction 2: si la ligne lue contient "TOTAL" en position 2, imprimer y
Instruction 3: imprimer de manière inconditionnelle la ligne lue.
Et voici le résultat obtenu:
Il est possible d'améliorer encore le résultat (pour par exemple afficher un titre), mais cela va compliquer (un tout petit peu) le script awk. Pour plus de clarté, plaçons le script modifié dans un fichier que nous appelons bilan.awk (les conditions sont en rouge):
NR == 1 {
while (a++<=length($0)/2-5) x=x " "
print "\n" x "Bilan" "\n" x "+++++" "\n"
}
NR == 2 {
y=gensub(/-/,"=","G")
}
/^ TOTAL/ {
print y
}
1
while (a++<=length($0)/2-5) x=x " "
print "\n" x "Bilan" "\n" x "+++++" "\n"
}
NR == 2 {
y=gensub(/-/,"=","G")
}
/^ TOTAL/ {
print y
}
1
Instruction 1: elle comprend deux actions conditionnées par NR == 1, donc qui s'exécutent seulement à la lecture de la première ligne.
Action 1: construction d'une chaîne d'espaces dans le but de centrer le mot "Bilan"
Action 2: impression du titre ("\n" est le caractère de contrôle nouvelle ligne)
Instruction 2: on sauvegarde dans y la ligne lue (ligne 2) dans laquelle on a remplacé tous les "-" par des "=".
Les deux instructions restantes sont inchangées.
Plaçons en tête du fichier bilan.sql la méta-commande:
\o | awk -f bilan.awk
Testons le résultat:
Si nous voulons envoyer le résultat obtenu vers un fichier bilan.txt tout en gardant l'affichage à l'écran, il suffit d'utiliser un deuxième tube:
\o | awk -f bilan.awk | tee bilan.txt
Il nous est bien sûr loisible de ne rien envoyer vers l'écran:
\o | awk -f bilan.awk > bilan.txt
Sunday, 18 December 2011
Jointures et autres requêtes sql
Dans notre base de données PostgreSQL de test, nous créons deux tables à l'aide des instructions SQL suivantes:

Nous aimerions maintenant faire apparaître à la suite de chaque opération le libellé de la contrepartie. Pour ce faire nous devons réaliser une jointure entre les deux tables. Diverses possibilités s'offrent à nous.
Jointure intérieure (INNER JOIN):
Les deux colonnes qui sont jointes portent le même nom. Dans ce cas, nous aurions pu arriver au même résultat avec le query suivant:
Nous devons donc utiliser un autre type de jointure:
Jointure extérieure gauche (LEFT OUTER JOIN):
Jointure externe droite (RIGHT OUTER JOIN)
Et enfin...
Jointure complète (FULL JOIN)
Dans la table opération tous les montants sont dans une seule colonne. Il est possible de les afficher sur deux colonnes, une réservée aux crédits et une autre pour les débits:
Exportation vers un tableur
L'output de la requête ci-dessus peut-être redirigé vers un fichier et formaté de manière telle que les données puissent être facilement exportées vers un tableur. Pour ce faire, il suffit d'utiliser dans notre terminal psql les meta commandes suivantes:
\pset numericlocale (pour avoir par exemple 1.460,45 au lieu de 1460.45)
\a pour passer au mode de sortie non aligné
\t pour afficher uniquement les rangées (sans les en-têtes)
\f ';' pour initialiser le séparateur de champ à ';'
\o [FICHIER] pour envoyer le résultat de la requête vers le fichier FICHIER
\i [FICHIER] pour exécuter les commande du fichier FICHIER (ce n'est évidemment pas le même)
Rapidement nous arrivons à ceci:


Ce query:

CREATE TABLE opération
(jour CHAR(8),
seq SMALLINT,
montant NUMERIC(13,2),
contrepartie CHAR(5),
PRIMARY KEY (jour, seq))
;
CREATE TABLE contrepartie
(contrepartie CHAR(5) PRIMARY KEY,
libellé VARCHAR(50))
;
et nous y plaçons quelques données, données que nous pouvons facilement retrouver grâce à des requêtes SQL élémentaires, exécutées par exemple dans un terminal psql:(jour CHAR(8),
seq SMALLINT,
montant NUMERIC(13,2),
contrepartie CHAR(5),
PRIMARY KEY (jour, seq))
;
CREATE TABLE contrepartie
(contrepartie CHAR(5) PRIMARY KEY,
libellé VARCHAR(50))
;
Nous aimerions maintenant faire apparaître à la suite de chaque opération le libellé de la contrepartie. Pour ce faire nous devons réaliser une jointure entre les deux tables. Diverses possibilités s'offrent à nous.
Jointure intérieure (INNER JOIN):
bdtest=> SELECT a.jour, a.seq, a.montant, b.libellé
bdtest-> FROM opération a INNER JOIN contrepartie b
bdtest-> ON a.contrepartie = b.contrepartie
bdtest-> ORDER BY a.jour, a.seq
bdtest-> ;
jour | seq | montant | libellé
----------+-----+---------+----------------
2011-255 | 2 | -400.00 | Epargne #1
2011-255 | 3 | -123.29 | Grande Surface
2011-255 | 4 | -150.00 | Alphonse
2011-256 | 2 | 57.49 | Epargne #2
(4 lignes)
Le mot INNER est facultatif car il s'agit du type de jointure par défaut.bdtest-> FROM opération a INNER JOIN contrepartie b
bdtest-> ON a.contrepartie = b.contrepartie
bdtest-> ORDER BY a.jour, a.seq
bdtest-> ;
jour | seq | montant | libellé
----------+-----+---------+----------------
2011-255 | 2 | -400.00 | Epargne #1
2011-255 | 3 | -123.29 | Grande Surface
2011-255 | 4 | -150.00 | Alphonse
2011-256 | 2 | 57.49 | Epargne #2
(4 lignes)
Les deux colonnes qui sont jointes portent le même nom. Dans ce cas, nous aurions pu arriver au même résultat avec le query suivant:
SELECT a.jour, a.seq, a.montant, b.libellé
FROM opération a NATURAL JOIN contrepartie b
ORDER BY a.jour
;
Un problème se pose: toutes les opérations ne sont pas reprises.FROM opération a NATURAL JOIN contrepartie b
ORDER BY a.jour
;
Nous devons donc utiliser un autre type de jointure:
Jointure extérieure gauche (LEFT OUTER JOIN):
bdtest=> SELECT a.jour, a.seq, a.montant, b.libellé
bdtest-> FROM opération a NATURAL LEFT OUTER JOIN contrepartie b
bdtest-> ORDER BY a.jour, a.seq
bdtest-> ;
jour | seq | montant | libellé
----------+-----+---------+----------------
2011-255 | 1 | 1460.45 |
2011-255 | 2 | -400.00 | Epargne #1
2011-255 | 3 | -123.29 | Grande Surface
2011-255 | 4 | -150.00 | Alphonse
2011-256 | 1 | -48.00 |
2011-256 | 2 | 57.49 | Epargne #2
2011-257 | 1 | -28.27 |
(7 lignes)
Lorsque la colonne a.contrepartie contient une valeur qui n'existe pas dans la table contrepartie, le système joint à la rangée concernée de la table opération une rangée (fictive) de la table contrepartie dont tous les champs sont à la valeur NULL. En ajoutant une clause WHERE au query précédent (et en modifiant aussi la clause SELECT), nous pouvons établir une liste des contreparties dont le libellé manque:bdtest-> FROM opération a NATURAL LEFT OUTER JOIN contrepartie b
bdtest-> ORDER BY a.jour, a.seq
bdtest-> ;
jour | seq | montant | libellé
----------+-----+---------+----------------
2011-255 | 1 | 1460.45 |
2011-255 | 2 | -400.00 | Epargne #1
2011-255 | 3 | -123.29 | Grande Surface
2011-255 | 4 | -150.00 | Alphonse
2011-256 | 1 | -48.00 |
2011-256 | 2 | 57.49 | Epargne #2
2011-257 | 1 | -28.27 |
(7 lignes)
bdtest=> SELECT DISTINCT a.contrepartie
bdtest-> FROM opération a NATURAL LEFT OUTER JOIN contrepartie b
bdtest-> WHERE b.contrepartie IS NULL
bdtest-> order by a.contrepartie
bdtest-> ;
contrepartie
--------------
autre
EL
RN
(3 lignes)
D'autres queries conduisent au même résultat:bdtest-> FROM opération a NATURAL LEFT OUTER JOIN contrepartie b
bdtest-> WHERE b.contrepartie IS NULL
bdtest-> order by a.contrepartie
bdtest-> ;
contrepartie
--------------
autre
EL
RN
(3 lignes)
SELECT DISTINCT a.contrepartie
FROM opération a
WHERE NOT EXISTS
(SELECT *
FROM contrepartie b
WHERE b.contrepartie = a.contrepartie)
ORDER by a.contrepartie
;
ou encore:FROM opération a
WHERE NOT EXISTS
(SELECT *
FROM contrepartie b
WHERE b.contrepartie = a.contrepartie)
ORDER by a.contrepartie
;
SELECT DISTINCT contrepartie
FROM opération
WHERE contrepartie NOT IN
(SELECT contrepartie
FROM contrepartie )
ORDER by contrepartie
;
Nous n'avons pas épuisé toutes les possibilités en ce qui concerne les types de jointures:FROM opération
WHERE contrepartie NOT IN
(SELECT contrepartie
FROM contrepartie )
ORDER by contrepartie
;
Jointure externe droite (RIGHT OUTER JOIN)
bdtest=> SELECT a.jour, a.seq, a.montant, b.libellé
bdtest-> FROM opération a NATURAL RIGHT OUTER JOIN contrepartie b
bdtest-> ORDER BY a.jour
bdtest-> ;
jour | seq | montant | libellé
----------+-----+---------+----------------
2011-255 | 2 | -400.00 | Epargne #1
2011-255 | 3 | -123.29 | Grande Surface
2011-255 | 4 | -150.00 | Alphonse
2011-256 | 2 | 57.49 | Epargne #2
| | | Magasin
(5 lignes)
Cette fois tous les libellés de la table de droite font partie du résultat, qu'il y ait ou non des opérations correspondantes.bdtest-> FROM opération a NATURAL RIGHT OUTER JOIN contrepartie b
bdtest-> ORDER BY a.jour
bdtest-> ;
jour | seq | montant | libellé
----------+-----+---------+----------------
2011-255 | 2 | -400.00 | Epargne #1
2011-255 | 3 | -123.29 | Grande Surface
2011-255 | 4 | -150.00 | Alphonse
2011-256 | 2 | 57.49 | Epargne #2
| | | Magasin
(5 lignes)
Et enfin...
Jointure complète (FULL JOIN)
bdtest=> SELECT a.jour, a.seq, a.montant, b.libellé
bdtest-> FROM opération a NATURAL FULL JOIN contrepartie b
bdtest-> ORDER BY a.jour
bdtest-> ;
jour | seq | montant | libellé
----------+-----+---------+----------------
2011-255 | 1 | 1460.45 |
2011-255 | 2 | -400.00 | Epargne #1
2011-255 | 3 | -123.29 | Grande Surface
2011-255 | 4 | -150.00 | Alphonse
2011-256 | 1 | -48.00 |
2011-256 | 2 | 57.49 | Epargne #2
2011-257 | 1 | -28.27 |
| | | Magasin
(8 lignes)
Répartition sur deux colonnes des crédits et des débitsbdtest-> FROM opération a NATURAL FULL JOIN contrepartie b
bdtest-> ORDER BY a.jour
bdtest-> ;
jour | seq | montant | libellé
----------+-----+---------+----------------
2011-255 | 1 | 1460.45 |
2011-255 | 2 | -400.00 | Epargne #1
2011-255 | 3 | -123.29 | Grande Surface
2011-255 | 4 | -150.00 | Alphonse
2011-256 | 1 | -48.00 |
2011-256 | 2 | 57.49 | Epargne #2
2011-257 | 1 | -28.27 |
| | | Magasin
(8 lignes)
Dans la table opération tous les montants sont dans une seule colonne. Il est possible de les afficher sur deux colonnes, une réservée aux crédits et une autre pour les débits:
bdtest=> SELECT jour, seq, libellé,
bdtest-> CASE
bdtest-> WHEN montant > 0 THEN
bdtest-> montant
bdtest-> ELSE 0
bdtest-> END AS credit,
bdtest-> CASE
bdtest-> WHEN montant < 0 THEN
bdtest-> -montant
bdtest-> ELSE 0
bdtest-> END AS debit
bdtest-> FROM opération NATURAL LEFT OUTER JOIN contrepartie
bdtest-> ORDER BY jour;
jour | seq | libellé | credit | debit
----------+-----+----------------+---------+--------
2011-255 | 1 | | 1460.45 | 0
2011-255 | 2 | Epargne #1 | 0 | 400.00
2011-255 | 3 | Grande Surface | 0 | 123.29
2011-255 | 4 | Alphonse | 0 | 150.00
2011-256 | 1 | | 0 | 48.00
2011-256 | 2 | Epargne #2 | 57.49 | 0
2011-257 | 1 | | 0 | 28.27
(7 lignes)
bdtest=> \w opération.sql
Après exécution de la requête, nous avons écrit celle-ci dans le fichier opération.sql en vue d'un usage ultérieur.bdtest-> CASE
bdtest-> WHEN montant > 0 THEN
bdtest-> montant
bdtest-> ELSE 0
bdtest-> END AS credit,
bdtest-> CASE
bdtest-> WHEN montant < 0 THEN
bdtest-> -montant
bdtest-> ELSE 0
bdtest-> END AS debit
bdtest-> FROM opération NATURAL LEFT OUTER JOIN contrepartie
bdtest-> ORDER BY jour;
jour | seq | libellé | credit | debit
----------+-----+----------------+---------+--------
2011-255 | 1 | | 1460.45 | 0
2011-255 | 2 | Epargne #1 | 0 | 400.00
2011-255 | 3 | Grande Surface | 0 | 123.29
2011-255 | 4 | Alphonse | 0 | 150.00
2011-256 | 1 | | 0 | 48.00
2011-256 | 2 | Epargne #2 | 57.49 | 0
2011-257 | 1 | | 0 | 28.27
(7 lignes)
Exportation vers un tableur
L'output de la requête ci-dessus peut-être redirigé vers un fichier et formaté de manière telle que les données puissent être facilement exportées vers un tableur. Pour ce faire, il suffit d'utiliser dans notre terminal psql les meta commandes suivantes:
\pset numericlocale (pour avoir par exemple 1.460,45 au lieu de 1460.45)
\a pour passer au mode de sortie non aligné
\t pour afficher uniquement les rangées (sans les en-têtes)
\f ';' pour initialiser le séparateur de champ à ';'
\o [FICHIER] pour envoyer le résultat de la requête vers le fichier FICHIER
\i [FICHIER] pour exécuter les commande du fichier FICHIER (ce n'est évidemment pas le même)
bdtest=> \pset numericlocale
Affichage de la sortie numérique adaptée à la locale.
bdtest=> \t
Affichage des tuples seuls.
bdtest=> \f ';'
Le séparateur de champs est « ; ».
bdtest=> \o bilan.csv
bdtest=> \i opération.sql
bdtest=>
Ouvrons bilan.csv dans un tableur.Affichage de la sortie numérique adaptée à la locale.
bdtest=> \a
Le format de sortie est unaligned.bdtest=> \t
Affichage des tuples seuls.
bdtest=> \f ';'
Le séparateur de champs est « ; ».
bdtest=> \o bilan.csv
bdtest=> \i opération.sql
bdtest=>
Rapidement nous arrivons à ceci:
Bilans comme résultat de requêtes
L'idéal pour obtenir un bilan est d'utiliser un tableur. Il est également possible d'établir un rapport depuis un outil comme libreoffice base.
Cependant de simples requêtes permettent d'arriver à de bons résultats.
Ainsi:
SELECT jour, seq, libellé,
CASE
WHEN montant > 0 THEN
montant
ELSE 0
END AS credit,
CASE
WHEN montant < 0 THEN
-montant
ELSE 0
END AS debit,
montant AS solde
FROM opération NATURAL LEFT OUTER JOIN contrepartie
UNION
SELECT 'Total' AS jour, 0 AS seq, '' AS libellé,
sum(credit) AS credit,
sum(debit) AS debit,
sum(solde) AS solde
FROM (SELECT
CASE
WHEN montant > 0 THEN
montant
ELSE 0
END AS credit,
CASE
WHEN montant < 0 THEN
-montant
ELSE 0
END AS debit,
montant AS solde
FROM opération NATURAL LEFT OUTER JOIN contrepartie
) a
ORDER BY jour, seq
;
nous donne (on a laissé numericlocale activé):CASE
WHEN montant > 0 THEN
montant
ELSE 0
END AS credit,
CASE
WHEN montant < 0 THEN
-montant
ELSE 0
END AS debit,
montant AS solde
FROM opération NATURAL LEFT OUTER JOIN contrepartie
UNION
SELECT 'Total' AS jour, 0 AS seq, '' AS libellé,
sum(credit) AS credit,
sum(debit) AS debit,
sum(solde) AS solde
FROM (SELECT
CASE
WHEN montant > 0 THEN
montant
ELSE 0
END AS credit,
CASE
WHEN montant < 0 THEN
-montant
ELSE 0
END AS debit,
montant AS solde
FROM opération NATURAL LEFT OUTER JOIN contrepartie
) a
ORDER BY jour, seq
;
Ce query:
SELECT
jour,
sum(credit) AS credit,
sum(debit) AS debit,
sum(solde) as solde
FROM (SELECT jour,
CASE
WHEN montant > 0 THEN
montant
END AS credit,
CASE
WHEN montant < 0 THEN
-montant
END AS debit,
montant AS solde
FROM opération) a
GROUP BY jour
UNION
SELECT
'Total' AS jour,
sum(credit) AS credit,
sum(debit) AS debit,
sum(solde) AS solde
FROM (SELECT
CASE
WHEN montant > 0 THEN
montant
END AS credit,
CASE
WHEN montant < 0 THEN
-montant
END AS debit,
montant AS solde
FROM opération) a
ORDER BY jour
;
conduit au résultat:jour,
sum(credit) AS credit,
sum(debit) AS debit,
sum(solde) as solde
FROM (SELECT jour,
CASE
WHEN montant > 0 THEN
montant
END AS credit,
CASE
WHEN montant < 0 THEN
-montant
END AS debit,
montant AS solde
FROM opération) a
GROUP BY jour
UNION
SELECT
'Total' AS jour,
sum(credit) AS credit,
sum(debit) AS debit,
sum(solde) AS solde
FROM (SELECT
CASE
WHEN montant > 0 THEN
montant
END AS credit,
CASE
WHEN montant < 0 THEN
-montant
END AS debit,
montant AS solde
FROM opération) a
ORDER BY jour
;
Tuesday, 6 December 2011
Nokia terá tablet com Windows em 2012

A Nokia irá lançar um tabblet em junho de 2012. Pelo menos é o que garante o presidente da empresa na França, Paul Amsellem, em entrevista para o jornal francês "Les Echos". O executivo disse também que a empresa planeja lançar novos aparelhos Lumia com o sistema Windows Phone.
Embora Amsellem tenha dado uma data para o lançamento do aparelho com o novo sistema operacional da Microsoft, a companhia ainda não divulgou quando colocará nas lojas o novo Windows. Ele não divulgou maiores detalhes do produto na entrevista.
A Nokia não se manifestou sobre as declarações do presidente da companhia na França.
Sobre os celulares, Amsellem disse que o Lumia é como se fosse uma BMW, que serão lançados novos modelos mais sofisticados e outros mais baratos, que rodarão o sistema Windows Phone. A empresa já apresentou um modelo mais econômico, o Lumia 710, e irá apresentar os aparelhos mais sofisticados em 2012.
EDIÇÃO DA 2ª QUINZENA DE NOVEMBRO DA CRN BRASIL

Click aqui e leia a edição na íntegra... Material muito interessante e objetivo. Cadastre-se para receber as notícias da CRN Brasil (Newsletter).
Até mais.
Monday, 5 December 2011
PostgreSQL, systemctl et initdb
Démarrer ou arrêter un service s'effectue actuellement dans certaines distributions récentes via la commande systemctl.
Ainsi pour démarrer le service postgresql, il y a lieu d'utiliser:
Certaines exceptions existaient jusqu'à un passé récent:

Ici la première des deux commandes, celle qui sert à initialiser le cluster de données n'est pas redirigée.
Ce n'est plus le cas actuellement, avec Fedora 16 par exemple:

Pour initialiser le cluster de données PostgreSQL nous devons procéder en exécutant la commande initdb en tant que l'utilisateur postgres.
Avant d'exécuter initdb, définissons de manière durable la variable d'environnement PGDATA:
Précisons ici qu'il nous est loisible de créer par la commande createdb une base de données avec une localisation différente de celle du cluster généré par initdb, mais à condition de combiner l'option --template à l'option --locale, comme ceci:
Ainsi pour démarrer le service postgresql, il y a lieu d'utiliser:
# systemctl start postgresql.service
plutôt que# service postgresql start
car de toute façon la commande service est redirigée vers systemctl.Certaines exceptions existaient jusqu'à un passé récent:
Ici la première des deux commandes, celle qui sert à initialiser le cluster de données n'est pas redirigée.
Ce n'est plus le cas actuellement, avec Fedora 16 par exemple:
Pour initialiser le cluster de données PostgreSQL nous devons procéder en exécutant la commande initdb en tant que l'utilisateur postgres.
Avant d'exécuter initdb, définissons de manière durable la variable d'environnement PGDATA:
[root@rigel ~]# echo 'export PGDATA=/var/lib/pgsql/data' > /etc/profile.d/pgsql.sh
[root@rigel ~]# source /etc/profile.d/pgsql.sh
[root@rigel ~]# su postgres
bash-4.2$ initdb -A ident
Le premier utilisateur doit être créé par postgres. Il faut évidemment procéder après avoir démarré le service:[root@rigel ~]# source /etc/profile.d/pgsql.sh
[root@rigel ~]# su postgres
bash-4.2$ initdb -A ident
bash-4.2$ pg_ctl start
serveur en cours de démarrage
bash-4.2$ createuser toto
Le nouveau rôle est-il super-utilisateur ? (o/n) n
Le nouveau rôle est-il autorisé à créer des bases de données ? (o/n) o
Le nouveau rôle est-il autorisé à créer de nouveaux rôles ? (o/n) o
bash-4.2$
Nous aurions pu lancer initdb avec l'option --locale, comme montré dans ce billet, mais ce n'est normalement pas nécessaire sauf si on désire une localisation différente de celle du système d'exploitation.serveur en cours de démarrage
bash-4.2$ createuser toto
Le nouveau rôle est-il super-utilisateur ? (o/n) n
Le nouveau rôle est-il autorisé à créer des bases de données ? (o/n) o
Le nouveau rôle est-il autorisé à créer de nouveaux rôles ? (o/n) o
bash-4.2$
Précisons ici qu'il nous est loisible de créer par la commande createdb une base de données avec une localisation différente de celle du cluster généré par initdb, mais à condition de combiner l'option --template à l'option --locale, comme ceci:
[toto@rigel ~]$ createdb bd01 --locale=fr_FR.utf8 --template=template0
Enfin, pour automatiser le démarrage du service, la commande à utiliser est:[root@rigel ~]# systemctl enable postgresql.service
En effet chkconfig est maintenant inopérant.