
PostgreSQL est une base de données moderne et puissante. Nous allons dans ce billet expliquer comment démarrer avec PostgreSQL et comment l'utiliser et ce de la manière la plus simple possible.
Installation et démarrage
En principe, il suffit d'installer le paquet serveur (postgresql-server), le paquet client (postgresql) et les autres paquets indispensables s'installeront alors automatiquement par le jeu des dépendances. Le nom de ces paquets peut évidemment varier suivant la distribution. Par exemple chez Ubuntu, le paquet serveur est postgresql et le paquet client postgresql-client. Une fois l'installation terminée, la première opération consiste à initialiser la base de donnée. Ensuite seulement le service peut être démarré.

Il se peut que le nom du service ne soit pas exactement postgresql. Dans ce cas, taper service post + tabulation afin de trouver le bon nom.
Chez Ubuntu, l'option initdb n'est pas reconnue. On passe alors directement à la deuxième commande.
Création du premier utilisateur PostgreSQL (autre que l'administrateur)
L'installation du paquet postgresql-server a ajouté au système d'exploitation un nouvel utilisateur: postgres, administrateur PostgreSQL. C'est le seul utilisateur connu de notre système de bases de données. Il faut donc lui ajouter d'autres utilisateurs. On est obligé de devenir postgres avant de procéder. Pour ce faire, il faut être dans un terminal avec les droits du root (obtenu avec sudo -s chez Ubuntu), ou sinon le sytème demande le mot de passe de postgres.

On a ajouté à PostgreSQL un nouvel utilisateur: toto. celui-ci pourra créer des bases de données (option -d) et ajouter des utilisateurs tout en étant super-utilisateur (option -a). toto doit être un utilisateur du système d'exploitation (ce n'est pas absolument obligatoire, mais c'est une question de facilité). Le mieux est même que toto soit notre nom d'utilisateur.
Il suffit alors d'entrer deux fois la commande exit, et voilà, on est redevenu toto.
Création de la première base de données
Reste à créer la base de données et à s'y connecter:

A des fins d'organisation, un dosssier SQL a d'abord été créé puis on s'y est rendu. La commande createdb exécutée sans arguments a créé la base de données toto. On s'y connecte avec la commande psql lancée aussi sans arguments. Quoi de plus simple. Bien sûr, il est possible faire plus compliqué.
Une première table: les régions de France
Imaginons que nous disposions par exemple d'un fichier FRregions (placé dans le dossier SQL) des différentes régions de France:
01 Alsace
02 Aquitaine
03 Auvergne
04 Basse-Normandie
05 Bourgogne
06 Bretagne
07 Centre
08 Champagne-Ardenne
09 Corse
10 Franche-Comté
..................
que nous voudrions importer dans la base de données toto.
Il nous faut en premier créer une table où placer les données que l'on va importer. Inscrivons les instructions sql de création de la table:
CREATE TABLE frregions
(region_id CHAR(2) PRIMARY KEY,
region_nom CHAR(30));
(region_id CHAR(2) PRIMARY KEY,
region_nom CHAR(30));
dans petit fichier texte appelé Cfrregions que nous mettons dans le dossier SQL (comme tous les autres fichiers dont il sera question dans la suite).
Bien sûr on pourrait taper ces commandes directement dans le terminal psql, mais on les a mis dans un fichier. Alors, comment procéder? Il faut savoir que dans un terminal psql, on peut aussi taper des méta-commandes comme par exemple:
toto=# \i FICHIER
qui exécute les commande du fichier.
Et bien, procédons:

Nous sommes avertis qu'un index a été automatiquement créé. Dans la foulée, nous avons importé le fichier FRregions avec la méta-commande \copy. Pour que cette commande fonctionne sans aucun autre argument, les champs du fichier ne doivent pas être séparés par des espaces mais par un caractère de tabulation qui est le séparateur par défaut.
Vérifions que tout c'est bien passé:

Et voilà le résultat:

(On s'est limité aux régions métropolitaines.)
Pour tester l'intégrité référentielle: la table des départements
Maintenant nous allons créer de la même façon une table des départements.
Le fichier des données:
01 Ain 22
02 Aisne 19
03 Allier 03
04 Alpes-de-Haute-Provence 21
05 Hautes-Alpes 21
06 Alpes-Maritimes 21
07 Ardèche 22
08 Ardennes 08
02 Aisne 19
03 Allier 03
04 Alpes-de-Haute-Provence 21
05 Hautes-Alpes 21
06 Alpes-Maritimes 21
07 Ardèche 22
08 Ardennes 08
........
De nouveau, il n'y a pas de blancs mais des caractères de tabulation. Les numéros en fin de lignes se rapportent à la région.Les instructions SQL de création de la table:
CREATE TABLE frdepartem
(departem_id CHAR(2) PRIMARY KEY,
departem_nom CHAR(30),
code_region CHAR(2) REFERENCES frregions);
(departem_id CHAR(2) PRIMARY KEY,
departem_nom CHAR(30),
code_region CHAR(2) REFERENCES frregions);
La dernière ligne de ces instructions implique que les données du champ code_region devront absolument faire référence à une région existante. La contrainte imposée dans cette dernière ligne est appelée une contrainte d'intégrité référentielle. En clair, un département doit se trouver dans une région.
Après en avoir terminé avec la création de cette nouvelle table, essayons de muter le département des Ardennes vers la région 23:

Et si maintenant, j'essaye de détruire une rangée de la table frregions:
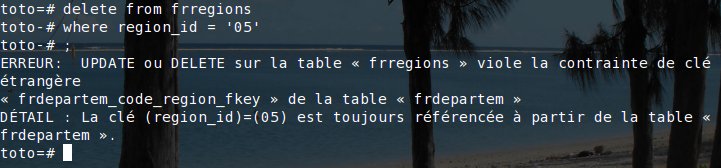
PostgreSQL garantit l'intégité référentielle de nos données.
Affichage html des données
Considérons la requête suivante:
select departem_id as "Numéro", departem_nom as "Département" , region_nom as "Région"
from frdepartem, frregions
where code_region = region_id
;
from frdepartem, frregions
where code_region = region_id
;
contenue dans le fichier sdepreg. Le terminal psql permet l'envoi du résultat de cette requête dans un fichier html:

\H bascule le format de sortie vers l'html.
Comme cela n'a pas tellement se sens d'afficher de l'html dans le terminal psql, on redirige la sortie vers le fichier depreg.html avec la commande
\ o depreg.html
Comme cela n'a pas tellement se sens d'afficher de l'html dans le terminal psql, on redirige la sortie vers le fichier depreg.html avec la commande
\ o depreg.html
Et voici ce que cela donne:

Ensuite:
\o supprime la redirection
\H revient au format de sortie précédent
Et pourquoi pas une table des codes postaux?
Notre base de données ne serait pas complète sans une table avec les codes postaux. Pour charger cette future table, nous disposons d'un fichier FRcp0 dont voici un extrait:
.......
25720 Aveney 25
25720 Beure 25
25720 Arguel 25
25720 Larnod 25
25720 Avanne-Aveney 25
25720 Pugey 25
25750 Aibre 25
25750 Le Vernoy 25
25720 Beure 25
25720 Arguel 25
25720 Larnod 25
25720 Avanne-Aveney 25
25720 Pugey 25
25750 Aibre 25
25750 Le Vernoy 25
25750 Semondans 25
25750 Désandans 25
25750 Arcey 25
25750 Désandans 25
25750 Arcey 25
.......
On aimerait associer au code postal un numéro séquentiel de manière à pouvoir différencier les différentes entrées relatives à un même code postal.
Nous allons utiliser awk après avoir trié le fichier:
[toto@rigel SQL]$ sort FRcp0 | awk 'BEGIN {FS="\t"}; x==$1 {i++}; !(x==$1) {i=1}; {x=$1};{print $1"\t"i"\t"$2"\t"$3}' > FRcp1
[toto@rigel SQL]$
Dans la clause BEGIN, nous demandons que le séparateur de champ soit un caractère de tabulation. Ensuite si x est égal au champ 1 (le code postal), nous incrémentons i de 1 (évidemment pour la première ligne ce n'est pas le cas). Si x n'est pas égal au champ 1, nous donnons à i la valeur 1, puis seulement nous mettons le champ 1 dans x.
On obtient ceci:
.....
25720 1 Arguel 25
25720 2 Avanne-Aveney 25
25720 3 Aveney 25
25720 4 Beure 25
25720 5 Larnod 25
25720 6 Pugey 25
25750 1 Aibre 25
25750 2 Arcey 25
25750 3 Désandans 25
25750 4 Le Vernoy 25
25750 5 Semondans 25
25720 2 Avanne-Aveney 25
25720 3 Aveney 25
25720 4 Beure 25
25720 5 Larnod 25
25720 6 Pugey 25
25750 1 Aibre 25
25750 2 Arcey 25
25750 3 Désandans 25
25750 4 Le Vernoy 25
25750 5 Semondans 25
.....
Et voici le fichier Cfrcp avec les instructions SQL de création de la table:
CREATE TABLE frcp
(code_postal CHAR(5),
cp_seq smallint,
localite_nom CHAR(50),
code_departem CHAR(2) REFERENCES frdepartem,
PRIMARY KEY (code_postal,cp_seq));
L'instruction PRIMARY KEY permettra la création d'une relation d'intégrité référentielle entre une future table d'adresses et la table des codes postaux. Cette table des adresses ne contiendra pas le nom de la localité, mais contiendra pour chaque rangée un code postal associé à un numéro de séquence qui devra désigner impérativement une rangée de la table des codes postaux.
Allons-y pour la création de cette table des codes postaux:

Et oui! Tout ne se passe pas toujours comme prévu. De nouveau une contrainte d'intégrité référentielle qui est violée.
L'erreur est clairement expliquée: le fichier FRcp1 comprend des lignes avec un code département qui est un blanc. Or il n'existe pas dans la table frdepartem de département sans code.
Le résultat de l'instruction select * from frcp montre qu'aucune rangée n'a été importée (en tout cas elles ne sont pas accessibles). Un comportement envisageable aurait été que seules les rangées en erreur n'aient pas été importées. Il reste à identifier les lignes fautives:
[toto@rigel SQL]$ awk '/[^0-9AB]$/{print NR}' Frcp1
5491
5493
5494
5495
9452
13868
5491
5493
5494
5495
9452
13868
à corriger le fichier et à recommencer l'import.
L'identification se base sur le fait que les lignes fautives ne se terminent pas par un chiffre, ni par un A, ni par un B (pour les deux départements corses).
PostgreSQL et les expressions régulières
PostgreSQL supporte l'emploi d'expressions régulières dans les instructions sql. Pourquoi ne pas essayer avec cette nouvelle table des codes postaux:

Ici nous avons recherché les noms de localité avec "bar" en sixième position. La première colonne reprend la sélection correspondant à l'expression régulière. Ensuite nous avons demandé l'affichage du nom complet de la localité ainsi que de son code postal.
Ce query est tellement extraordinaire que nous avons donné instruction de l'écrire dans le fichier sregexp. On pourra donc le ré-exécuter quand on veut avec la méta-commande: toto=# \i sregexp.
Pour conclure
Il existe des solutions graphiques pour accéder à une base de données PostgreSQL.
Dans un prochain billet nous verrons notamment comment procéder avec openoffice.
Post a Comment