
Considérons une requête sql, contenue dans un fichier et dont le résultat est envoyé par un tube vers la commande awk.
Le script à utiliser par awk dépend de la configuration.
Ainsi, si un titre a été défini par une méta-commande, la première ligne avec des données sera la ligne # 4 (au lieu de # 3).
Si de plus le style de bordure est de type 2, ce sera la ligne # 5.
C'est pourquoi il peut être utile de placer dans un fichier contenant une instruction de redirection vers un tube, les méta-commandes de configuration comme par exemple:
\pset title Rapport
Pour éviter de polluer l'output par des messages tels que:
Le titre est « Rapport »
il convient alors de définir en premier la variable d'environnement QUIET.
D'autre part, on voudrait aussi après exécution de la requêtre rétablir la configuration par défaut, de sorte qu'un tel fichier pourrait ressembler à ceci:
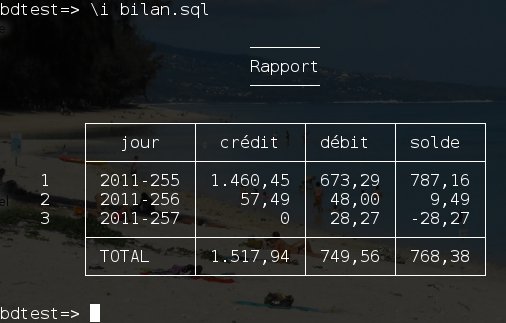
Ci dessus un script awk adapté à la présence d'un titre et à un style de bordure de niveau 2, servant à la mise en forme du titre et à l'impression d'une ligne de séparation avant une ligne "TOTAL" éventuelle:
La ligne u, au départ une copie de t, qui sera imprimée juste avant et juste après le titre, est modifiée dans un premier temps en remplaçant par a de tout ce qui n'appartient pas à la classe prédéfinie [:space:], et ensuite en remplaçant aussi (par a) les espaces qui sont au milieu de la chaîne des a (les espaces qui étaient contenus dans le titre).
Notes:
On obtient dans le cas d'un style de ligne unicode:

Le script peut être utilisé même en l’absence de ligne "TOTAL": il sert alors simplement à mettre en forme le titre.
Si le style de bordure est de niveau 1, il faut attendre la ligne 3 pour récupérer le caractère servant à tracer les lignes.
Le script (qui pourrait s'appeler titre-border-1.awk) se présente alors comme ceci:
Envisageons maintenant d'envoyer le résultat d'une requête vers un tube afin d'en numéroter les lignes avec cette méta-commande:
Nous utilisons printf afin que les numéros des lignes soient justifiés à droite: on imprime d'abord NR en tant que nombre décimal précédé d'espaces jusqu'à atteindre la longueur 5 (%5d), un caractère de tabulation (\t), ensuite la ligne reçue en input en tant que chaîne de caractères (%s).
Notons que printf (contrairement à print) ne met pas de caractère nouvelle ligne (\n) à la fin de son envoi. Il doit donc être explicitement ajouté.
En présence d'un titre et avec un style de bordure de niveau 1, on obtient:

Bien sûr, on voudrait seulement numéroter les lignes de données et en plus mettre en forme le titre et séparer la ligne "TOTAL" éventuelle du reste.
Pour ce faire, il suffit par exemple, d'adapter le script précédent (qui convient pour un style de bordure de niveau 1):
L'utilisation du script ci-dessus nous donne:

Adapter pour la numérotation le script convenant pour le style de bordure de niveau 2 est un peu plus ardu.
Le problème est d'éviter la numérotation de la dernière ligne non vide (qui fait partie du cadre):
Et voici le résultat:
Les scripts awk présentés ici dépendent certes du style de bordure et de la présence d'un titre, mais ils sont indépendants du style de ligne.
Par exemple avec un autre style de ligne, une autre table et un autre titre, l'utilisation du même script donne ceci:

Le script à utiliser par awk dépend de la configuration.
Ainsi, si un titre a été défini par une méta-commande, la première ligne avec des données sera la ligne # 4 (au lieu de # 3).
Si de plus le style de bordure est de type 2, ce sera la ligne # 5.
C'est pourquoi il peut être utile de placer dans un fichier contenant une instruction de redirection vers un tube, les méta-commandes de configuration comme par exemple:
\pset title Rapport
Pour éviter de polluer l'output par des messages tels que:
Le titre est « Rapport »
il convient alors de définir en premier la variable d'environnement QUIET.
D'autre part, on voudrait aussi après exécution de la requêtre rétablir la configuration par défaut, de sorte qu'un tel fichier pourrait ressembler à ceci:
\set QUIET
\pset numericlocale on
\pset footer off
\pset linestyle u
\pset title 'Rapport'
\pset border 2
\o | awk -f titre-border-2.awk | tee Rapport.txt
--++++++++++++++++++++++++++++++++++++++++++++++
-- Début de la requête
--++++++++++++++++++++++++++++++++++++++++++++++
SELECT ....
......
;
--++++++++++++++++++++++++++++++++++++++++++++++
-- Fin de la requête
--++++++++++++++++++++++++++++++++++++++++++++++
\o
\pset footer
\pset title
\pset border 1
\unset QUIET
(Notons l'utilisation, comme il se doit en sql, de -- pour commenter une ligne)\pset numericlocale on
\pset footer off
\pset linestyle u
\pset title 'Rapport'
\pset border 2
\o | awk -f titre-border-2.awk | tee Rapport.txt
--++++++++++++++++++++++++++++++++++++++++++++++
-- Début de la requête
--++++++++++++++++++++++++++++++++++++++++++++++
SELECT ....
......
;
--++++++++++++++++++++++++++++++++++++++++++++++
-- Fin de la requête
--++++++++++++++++++++++++++++++++++++++++++++++
\o
\pset footer
\pset title
\pset border 1
\unset QUIET
Ci dessus un script awk adapté à la présence d'un titre et à un style de bordure de niveau 2, servant à la mise en forme du titre et à l'impression d'une ligne de séparation avant une ligne "TOTAL" éventuelle:
# Sauvegarde du titre dans t et u
NR == 1 {
t=$0
u=t
}
# Récupération du caractère pour tracer les lignes
# Impression du titre
NR == 2 {
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
}
# Sauvegarde ligne de séparation dans y
NR == 4 {
y=$0
}
/^..TOTAL/ {
print y
}
# Ne plus imprimer le titre (ligne # 1)
NR > 1
Le titre contenu dans $0 puis sauvegardé dans t est précédé du nombre d'espaces qui convient pour qu'il soit centré.NR == 1 {
t=$0
u=t
}
# Récupération du caractère pour tracer les lignes
# Impression du titre
NR == 2 {
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
}
# Sauvegarde ligne de séparation dans y
NR == 4 {
y=$0
}
/^..TOTAL/ {
print y
}
# Ne plus imprimer le titre (ligne # 1)
NR > 1
La ligne u, au départ une copie de t, qui sera imprimée juste avant et juste après le titre, est modifiée dans un premier temps en remplaçant par a de tout ce qui n'appartient pas à la classe prédéfinie [:space:], et ensuite en remplaçant aussi (par a) les espaces qui sont au milieu de la chaîne des a (les espaces qui étaient contenus dans le titre).
Notes:
- La lecture du billet "Expressions régulières" pourrait être utile en cas de difficulté de compréhension d'une notation telle que [^[:space:]]
- Il arrive que la classe [:space:] ne soit pas reconnue par le programme awk qui est appelé (c'est le cas chez Ubuntu où /etc/alternatives/awk pointe vers /usr/bin/mawk). Il convient alors d'installer gawk.
- Dans ce script (et dans les suivants) on pourrait remplacer [^[:space:]] par la notation abrégée \S (pas chez Ubuntu, même avec gawk installé).
- La classe [:space:] comprend outre les espaces, les caractères de contrôle tabulation (\t), tabulation verticale (\v), saut de page (\f), retour chariot (\r), nouvelle ligne (\n). Mais à l'intérieur du script, awk travaille sur des lignes qui ont été débarrassées de leur \n final. Celui-ci est remis par l'action "print".
- gsub retourne 1 en cas de substitution effectuée: il devient alors une condition vérifiée pour la commande while (qui est utile lorsque le titre comprend plusieurs espaces successifs).
- a a représente la concaténation de a et de a.
On obtient dans le cas d'un style de ligne unicode:
Le script peut être utilisé même en l’absence de ligne "TOTAL": il sert alors simplement à mettre en forme le titre.
Si le style de bordure est de niveau 1, il faut attendre la ligne 3 pour récupérer le caractère servant à tracer les lignes.
Le script (qui pourrait s'appeler titre-border-1.awk) se présente alors comme ceci:
# Sauvegarde du titre dans t et u
NR == 1 {
t=$0
u=t
}
# Sauvegarde des en-têtes dans h
NR == 2 {
h=$0
}
# Sauvegarde de la ligne de séparation dans y
# Récupération du caractère pour tracer les lignes
# Impression du titre puis des en-têtes
NR == 3 {
y=$0
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print h
}
/^.TOTAL/ {
print y
}
# Ne plus imprimer le titre et les en-têtes
NR > 2
NR == 1 {
t=$0
u=t
}
# Sauvegarde des en-têtes dans h
NR == 2 {
h=$0
}
# Sauvegarde de la ligne de séparation dans y
# Récupération du caractère pour tracer les lignes
# Impression du titre puis des en-têtes
NR == 3 {
y=$0
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print h
}
/^.TOTAL/ {
print y
}
# Ne plus imprimer le titre et les en-têtes
NR > 2
Envisageons maintenant d'envoyer le résultat d'une requête vers un tube afin d'en numéroter les lignes avec cette méta-commande:
\o | awk '{printf("%5d\t%s\n", NR, $0)}'
Nous utilisons printf afin que les numéros des lignes soient justifiés à droite: on imprime d'abord NR en tant que nombre décimal précédé d'espaces jusqu'à atteindre la longueur 5 (%5d), un caractère de tabulation (\t), ensuite la ligne reçue en input en tant que chaîne de caractères (%s).
Notons que printf (contrairement à print) ne met pas de caractère nouvelle ligne (\n) à la fin de son envoi. Il doit donc être explicitement ajouté.
En présence d'un titre et avec un style de bordure de niveau 1, on obtient:
Bien sûr, on voudrait seulement numéroter les lignes de données et en plus mettre en forme le titre et séparer la ligne "TOTAL" éventuelle du reste.
Pour ce faire, il suffit par exemple, d'adapter le script précédent (qui convient pour un style de bordure de niveau 1):
# Sauvegarde du titre dans t et u
NR == 1 {
t= "\t" $0
u=t
}
# Sauvegarde des en-têtes
NR == 2 {
h= "\t" $0
}
# Sauvegarde de la ligne de séparation dans y
# Impression du titre, des en-têtes et de la ligne de séparation qui suit
NR == 3 {
y= "\t" $0
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print h
print y
}
/^.TOTAL/ {
print y
print "\t" $0
}
# Numéroter puis imprimer les données
# Ne pas procéder pour la ligne TOTAL éventuelle, ni pour les lignes vides
NR > 3 && !/^.TOTAL/ && !/^$/ {
n++
printf("%5d\t%s\n", n, $0)
}
# Impression des lignes vides
/^$/
(u comprend maintenant un caractère de tabulation, mais comme ce caractère fait partie de la classe [:space:], cela ne change rien en ce qui concerne le résultat de gsub)NR == 1 {
t= "\t" $0
u=t
}
# Sauvegarde des en-têtes
NR == 2 {
h= "\t" $0
}
# Sauvegarde de la ligne de séparation dans y
# Impression du titre, des en-têtes et de la ligne de séparation qui suit
NR == 3 {
y= "\t" $0
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print h
print y
}
/^.TOTAL/ {
print y
print "\t" $0
}
# Numéroter puis imprimer les données
# Ne pas procéder pour la ligne TOTAL éventuelle, ni pour les lignes vides
NR > 3 && !/^.TOTAL/ && !/^$/ {
n++
printf("%5d\t%s\n", n, $0)
}
# Impression des lignes vides
/^$/
L'utilisation du script ci-dessus nous donne:
Adapter pour la numérotation le script convenant pour le style de bordure de niveau 2 est un peu plus ardu.
Le problème est d'éviter la numérotation de la dernière ligne non vide (qui fait partie du cadre):
# Sauvegarde du titre dans t et u
NR == 1 {
t= "\t" $0
u=t
}
# Impression du titre et de la partie supérieure du cadre
NR == 2 {
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print "\t" $0
}
# Impression des en-têtes
NR == 3 {
print "\t" $0
}
# Sauvegarde dans y et impression de la ligne de séparation
NR == 4 {
y= "\t" $0
print y
}
/^..TOTAL/ {
print y
print "\t" $0
}
# Impression de la partie inférieure du cadre
NR > 4 && substr($0,2,1)==a {
print "\t" $0
}
# Numéroter puis imprimer les données
# Ne pas procéder pour la ligne TOTAL éventuelle, ni pour les lignes vides
# ni pour les lignes de cadre
NR > 4 && !/^..TOTAL/ && !/^$/ && substr($0,2,1)!=a {
n++
printf("%5d\t%s\n", n, $0)
}
# Impression ligne vide
/^$/
NR == 1 {
t= "\t" $0
u=t
}
# Impression du titre et de la partie supérieure du cadre
NR == 2 {
a=substr($0,2,1)
gsub(/[^[:space:]]/,a,u)
while (gsub(/[^[:space:]] /,a a,u)) {
}
print "\n" u "\n" t "\n" u "\n"
print "\t" $0
}
# Impression des en-têtes
NR == 3 {
print "\t" $0
}
# Sauvegarde dans y et impression de la ligne de séparation
NR == 4 {
y= "\t" $0
print y
}
/^..TOTAL/ {
print y
print "\t" $0
}
# Impression de la partie inférieure du cadre
NR > 4 && substr($0,2,1)==a {
print "\t" $0
}
# Numéroter puis imprimer les données
# Ne pas procéder pour la ligne TOTAL éventuelle, ni pour les lignes vides
# ni pour les lignes de cadre
NR > 4 && !/^..TOTAL/ && !/^$/ && substr($0,2,1)!=a {
n++
printf("%5d\t%s\n", n, $0)
}
# Impression ligne vide
/^$/
Et voici le résultat:
Les scripts awk présentés ici dépendent certes du style de bordure et de la présence d'un titre, mais ils sont indépendants du style de ligne.
Par exemple avec un autre style de ligne, une autre table et un autre titre, l'utilisation du même script donne ceci:
Post a Comment