
What is Listener Configuration File? Listener is a process that resides on the server whose responsibility is to listen for incoming client ...

What is Listener Configuration File? Listener is a process that resides on the server whose responsibility is to listen for incoming client ...

Stands for "Database Management System." In short, a DBMS is a database program. Technically speaking, it is a software system ...
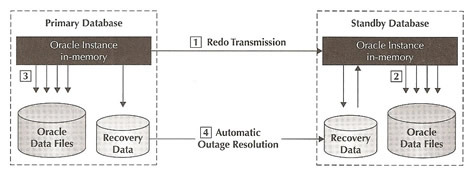
Oracle D ata Guard ensures high availability, data protection, and disaster recovery for enterprise data. Data Guard provides a comprehens...

In database management systems, a file that defines the basic organization of a database. A data dictionary contains a list of all files in ...

Stage tables For many applications with a database back end, stage tables are the first point of entry (or first line of defense, depending ...
What is PPP? Short for Point-to-Point Protocol, a method of connecting a computer to the Internet. PPP is more stable than the older SLIP ...